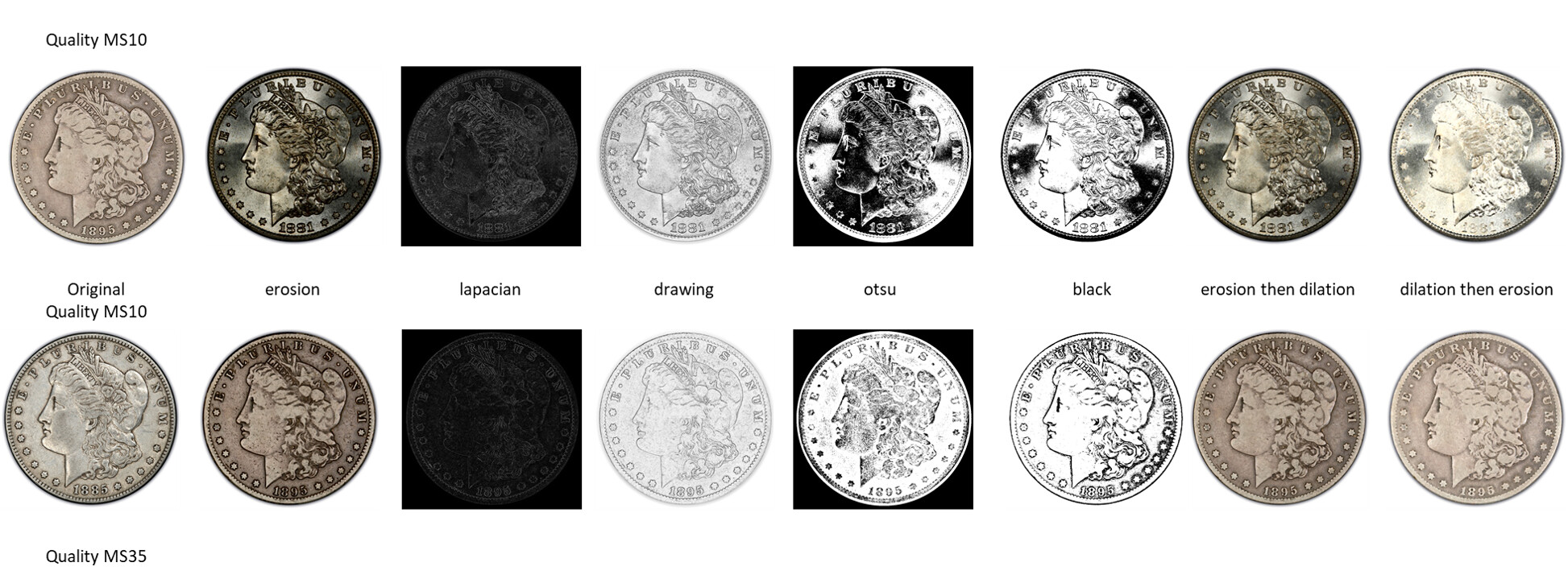
OK, here is how I backtracked to the good ‘inlier’ keypoints. probably not the most efficient way but brute force as a test.
you can see the output on iCollect and compare the image with all the matches with the one with the good matches.
let me know what you think before I start working on the rest of your feedback.
let findHomographyMask = new cv.Mat();//test
let h = cv.findHomography(mat1, mat2, cv.RANSAC, 3, findHomographyMask);
if (h.empty())
{
alert("homography matrix empty!");
return;
}
else{
let good_inlier_matches = new cv.DMatchVector();
for (let i = 0; i < findHomographyMask.rows; i=i+2) {
if(findHomographyMask.data[i] === 1 || findHomographyMask.data[i+1] === 1) {
let x = points2[i];
let y = points2[i + 1];
for (let j = 0; j < keypoints2.size(); ++j) {
if (x === keypoints2.get(j).pt.x && y === keypoints2.get(j).pt.y) {
for (let k = 0; k < good_matches.size(); ++k) {
if (j === good_matches.get(k).trainIdx) {
good_inlier_matches.push_back(good_matches.get(k));
}
}
}
}
}
}
var inlierMatches = new cv.Mat();
cv.drawMatches(im1, keypoints1, im2, keypoints2, good_inlier_matches, inlierMatches, color);
cv.imshow('inlierMatches', inlierMatches);
console.log("Good Matches: ", good_matches.size(), " inlier Matches: ", good_inlier_matches.size());
Here is an easy way to visualize and compare to the graphic in a previous post above:
also, not sure yet why when I pyrDown the matrix gets hosed (you can see it as I put an option for pyrDown at the top). Looking into that now but all i’m doing is calling it at the beginning of the script. makes me think this logic in the homography is still not correct.
correction, knn % of .5 works with pyrDown but now I’m wondering how to determine automatically what factor to use…
cv.pyrDown(im1, im1, new cv.Size(0, 0), cv.BORDER_DEFAULT);
cv.pyrDown(im2, im2, new cv.Size(0, 0), cv.BORDER_DEFAULT);




{kind=link}